神经网络
因为异或、圆形分布的数据无法用线性分类器解决,常规的解决方案有:第一种解决方案是将非线性的数据线性化,提取更高级的特征,第二种办法就是引入非线性的因素。人们想到在线性分类器上加入非线性的因素,使其能够对非线性的数据进行学习,变成非线性的模型,所以提出了神经网络的方法。
神经网络模型模拟的是动物和人的大脑的工作,对这个过程进行建模,得到在数学上的表达可以等价为:
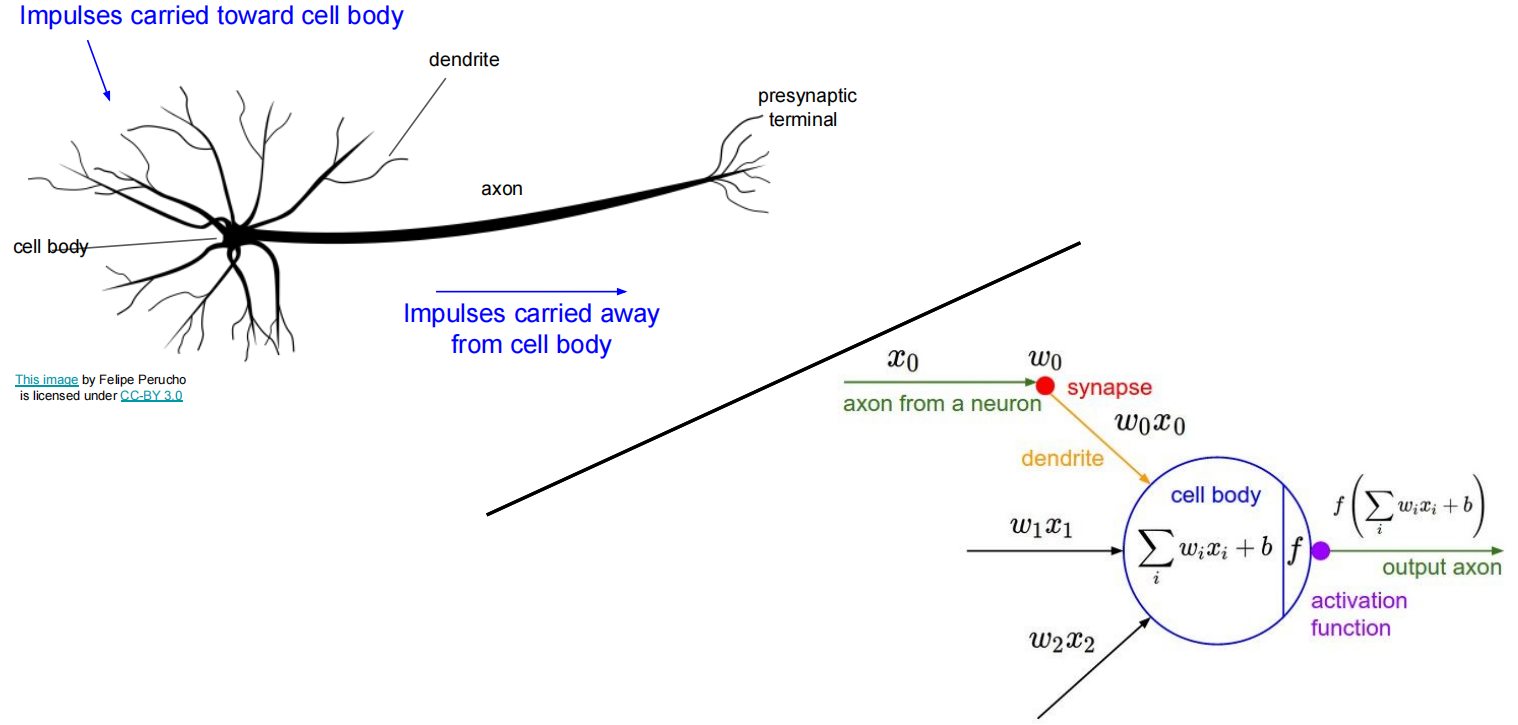
多个神经元堆叠:
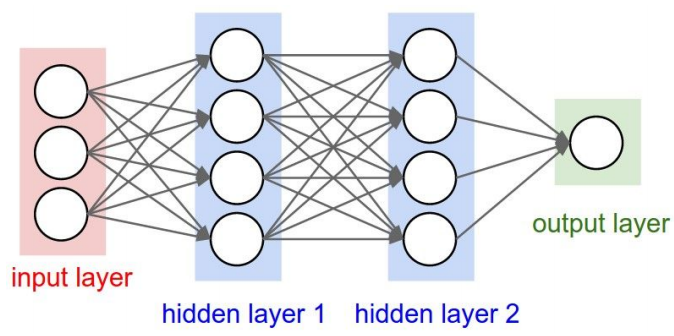
感知机(Perceptrons / Fully-Connected Networks)
激活函数
因为有非线性激活函数的存在,导致分类器的输出变成一个非线性的输出。给神经网络带来了模型上的非线性。常见的激活函数有:
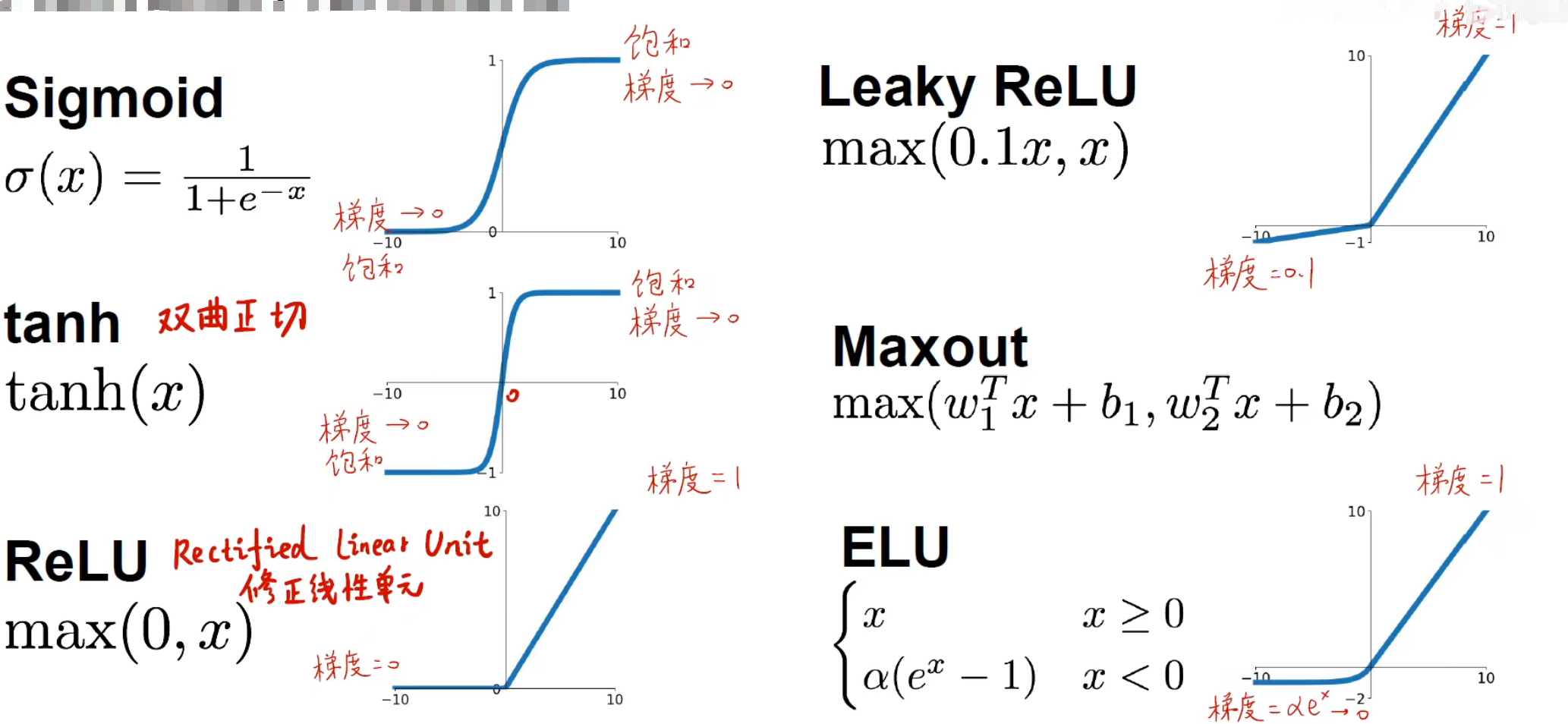
在这里不要简单看成普通的函数,因为在传播过程中, 轴代表了每次该层或者前面几层的线性计算结果(指代入线性函数公式),而且在更新权重的过程中需要对损失函数进行求导,而根据链式法则,要求损失函数的导数,需要对 进行求导,而一般 是被套在损失函数里面的,所以也需要对激活函数进行求导。对激活函数进行求导就能得到他的变化率,也就是梯度。
神经网络
一层里面每一个神经元都与前一层的所有神经元进行连接。
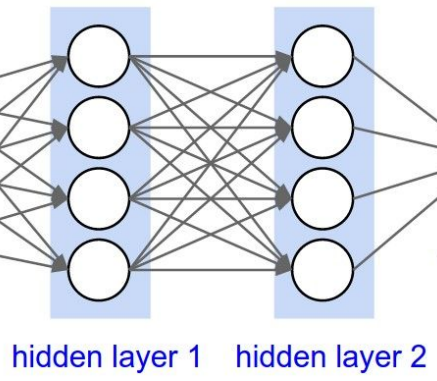
通过多次非线性的激活使得线性函数能够拟合非线性的数据。本质上还是以线性函数为基础传递和学习权重。通常的传播通过多次迭代线性函数,每一次迭代经过一个激活函数使其变得非线性,实现数据的前向传播。
使用图示可以这么表示:
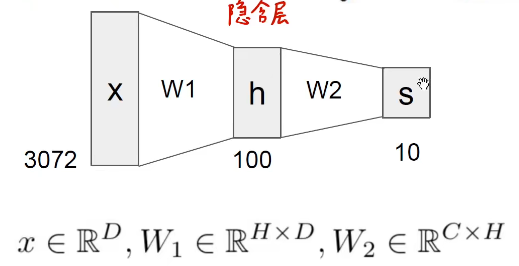
示例代码:
import numpy as np
from numpy .random import randn
N, D_in, H, D_out = 64,1000,100,10
x, y = randn(N, D_in),randn(N,D_out)
w1, w2 = randn(D_in, H), randn(H, D_out)
for t in range( 2000) :
h = 1 / (1 + np.exp(-x.dot(w1)))
y_pred = h.dot(w2)
loss = np.square(y_pred - y).sum()
print(t, loss)
grad_y_pred = 2.0* (y_pred - y)
grad_w2 = h.T.dot(grad_y_pred)
grad_h = grad_y_pred.dot(w2.T)
grad_w1 = x.T.dot(grad_h * h * (1 - h))
w1 -= 1e-4 * grad_w1
w2-= 1e-4 * grad_w2
神经网络的隐含层越多,神经元越多,说明可以提取到的特征就越抽象,越底层,更能找到其本质的特征。同时也能够导致过拟合。所以,神经网络不是越深越好,也不是越浅越好,要根据实际的数据来决定神经网络的层数,同时为了应对神经网络过拟合的问题,又提出了很多有关防止过拟合的方法。
上述代码的计算图示意:
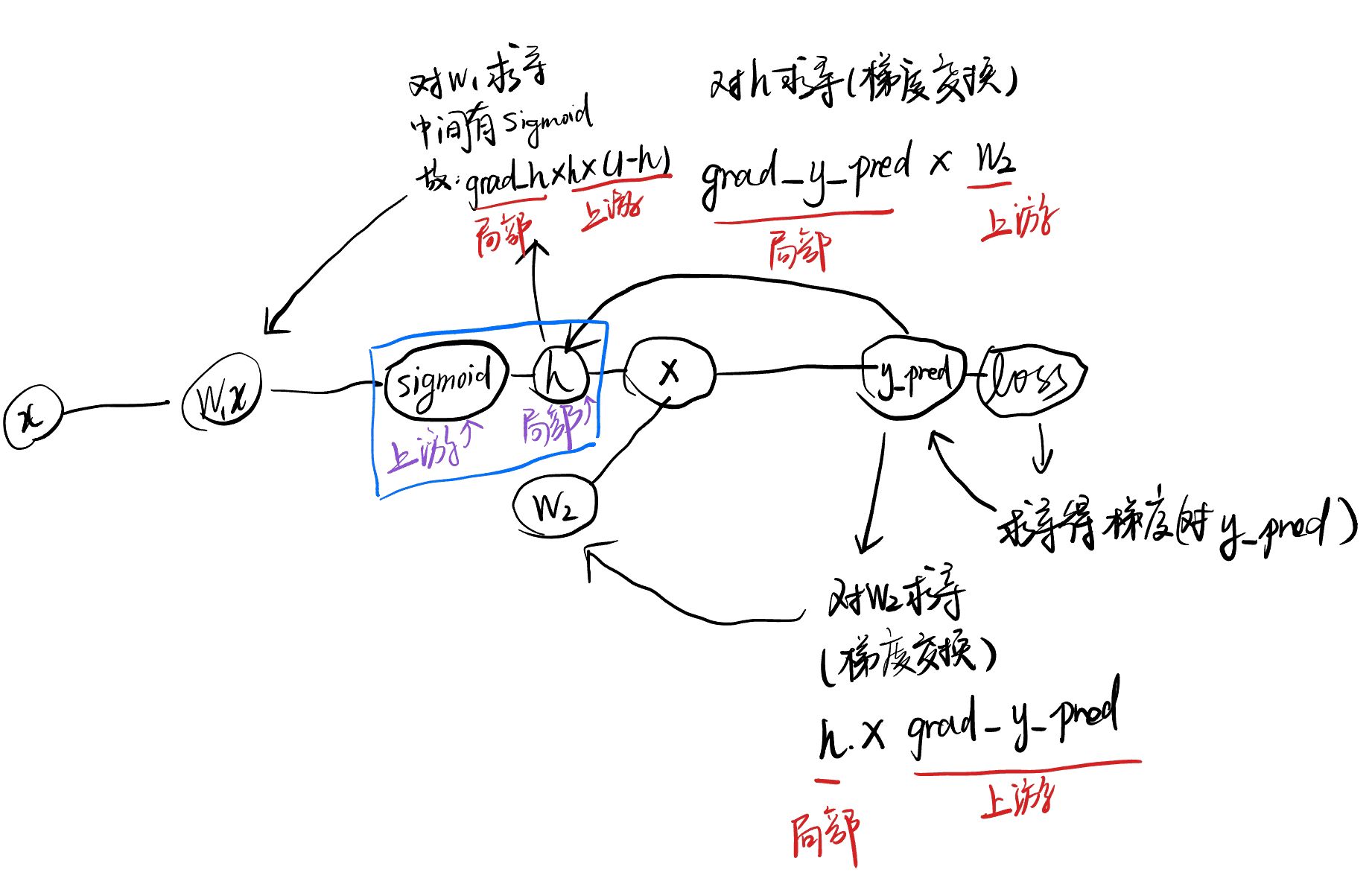
反向传播
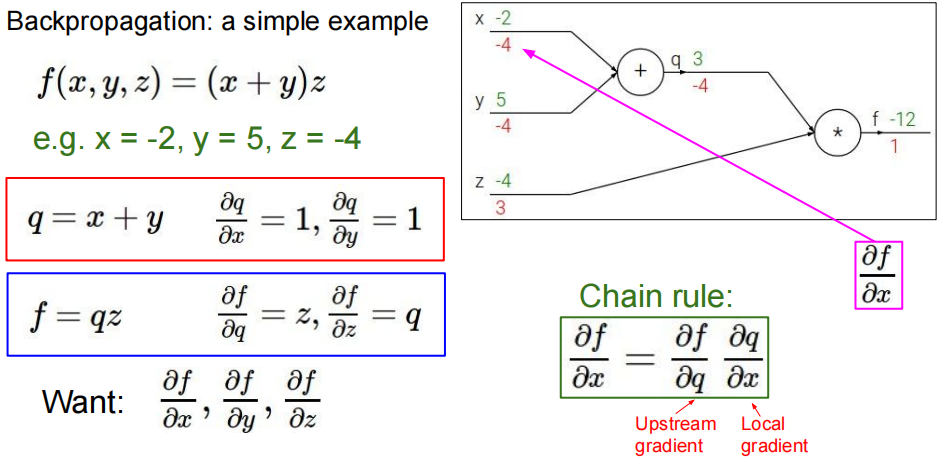
反向传播是神经网络训练的方法,根据前向传播的结果,使用链式法则反向求解各个计算节点的梯度,用梯度来更新所输入的权重。因为神经网络形式不固定,而且维度层数很高,数据维度高等因素,导致无法通过直接迭代等方式更新,所以就引入计算图和链式法则。
可以看到,对应各个变量的梯度计算如下:
- 对 的梯度:
- 对 的梯度:
- 对 的梯度:
- 对 的梯度:
随着计算图的长度增加,需要使用链式法则求导的长度就越长,求得之前的梯度都是通过前向传播之后得到的 反向求得 对各个变量的梯度。总结成通式为,前向传播结束后得到的变量 ,且 可微,则对于计算图中,中间经过的节点对应的变量 可得:
对于每一个变量都需要计算一个 对 的梯度,得到应该更新的值。
此处没有考虑到激活函数的情况,把计算图上所有的节点抽象成变量 ,只要是在计算图上的节点都要对其进行计算梯度。
本质上其实就是上游梯度乘以局部梯度,也就是前向传播终点乘以对前一个节点的梯度,再乘上这个节点对前一个变量的梯度。梯度常用的基本还是基于加、乘、求最值等运算方法,总结一下可以得到,这些运算的理解:
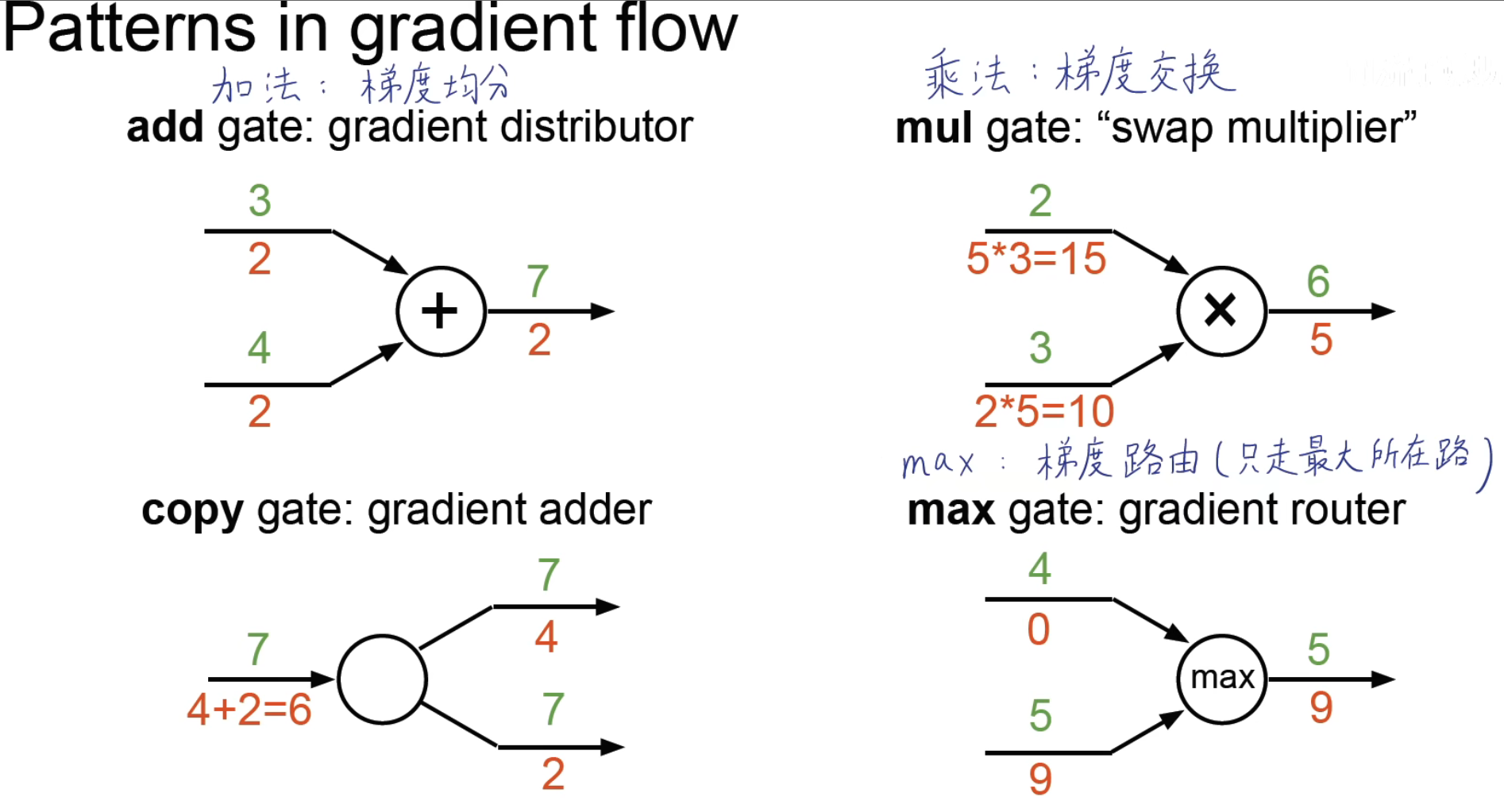
更多的例子:
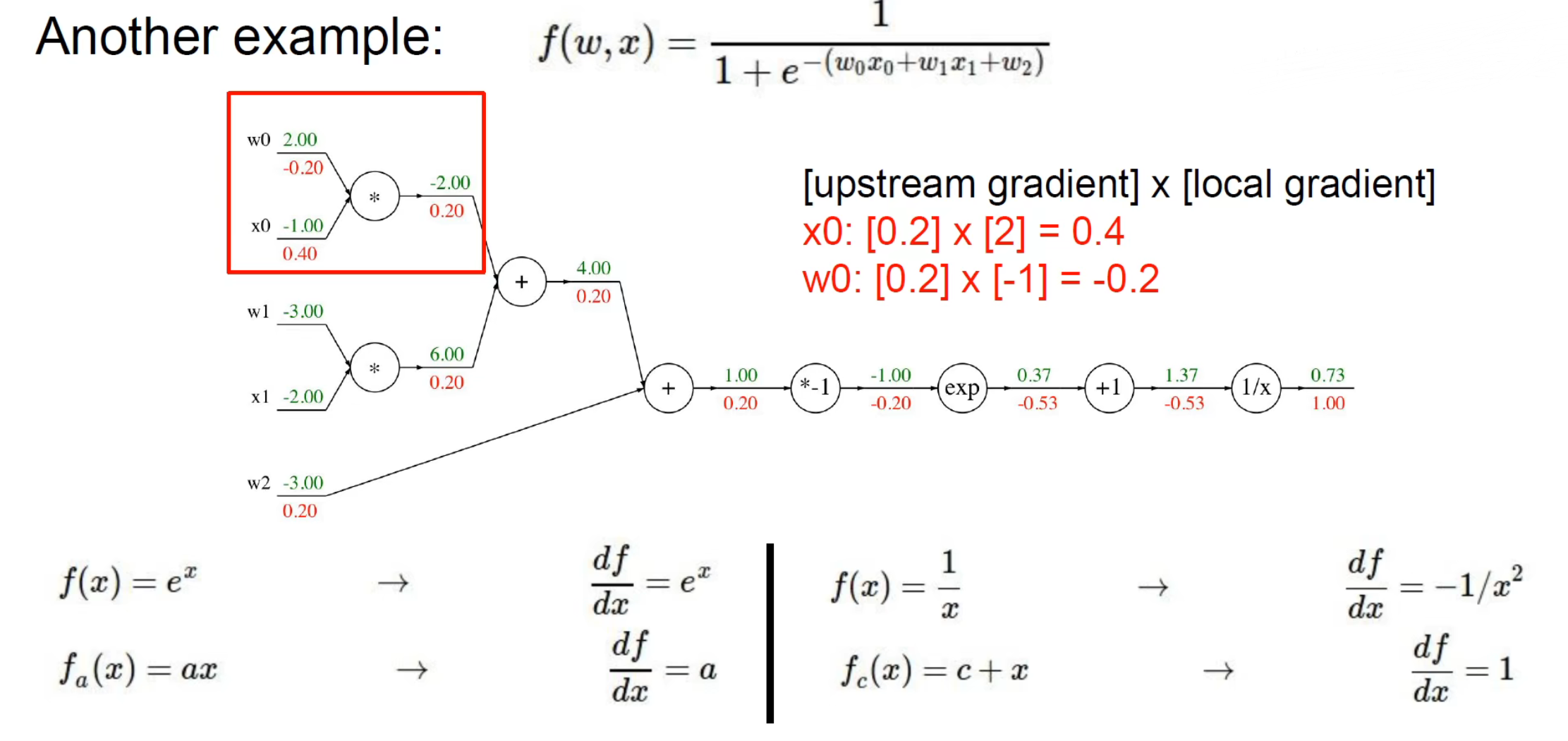
深度越深,特征能力表示越强,但是也越容易过拟合。
深度和宽度的选择原则,只有一个隐含层,只要神经元个数足够多,能够解决任何问题。
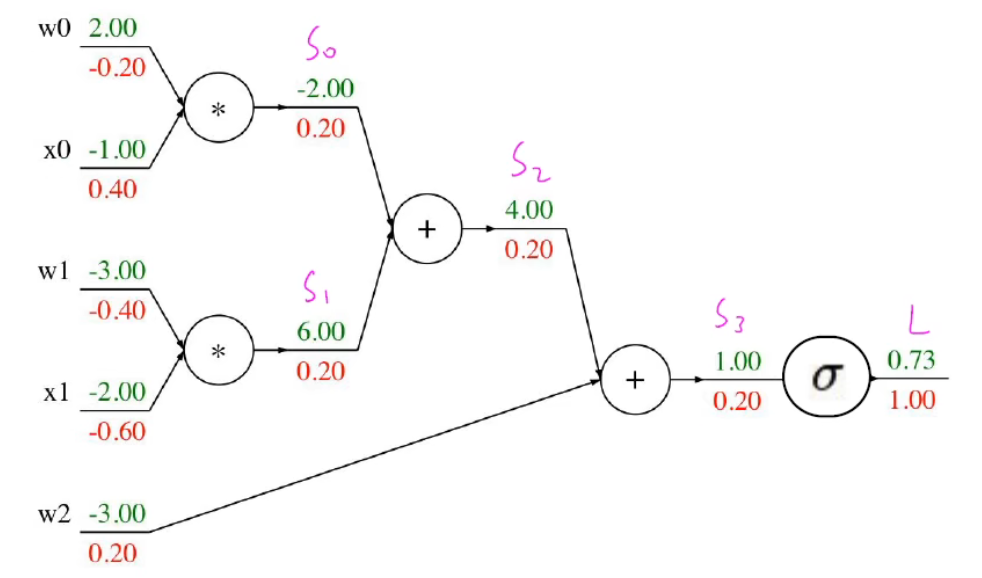
前向传播和反向传播示意代码:
def f(w0,x0,w1,x1,w2):
# forward
s= w * x0
s1 = w1 * x1
s2 = s0 + s1
s3 = s2 + w2
L = sigmoid(s3)
# backward
grad_L = 1.0
grad_s3 = grad_L * (1 - L) * L
grad_w2 = grad_s3
grad_s2 = grad_s3
grad_s0 = grad_s2
grad_s1 = grad_s2
grad_w1 = grad_s1 * x1
grad_x1 = grad_s1 * w1
grad_w0 = grad_s0 * x0
grad_x0 = grad_s0 * w0
对应的计算图如下:
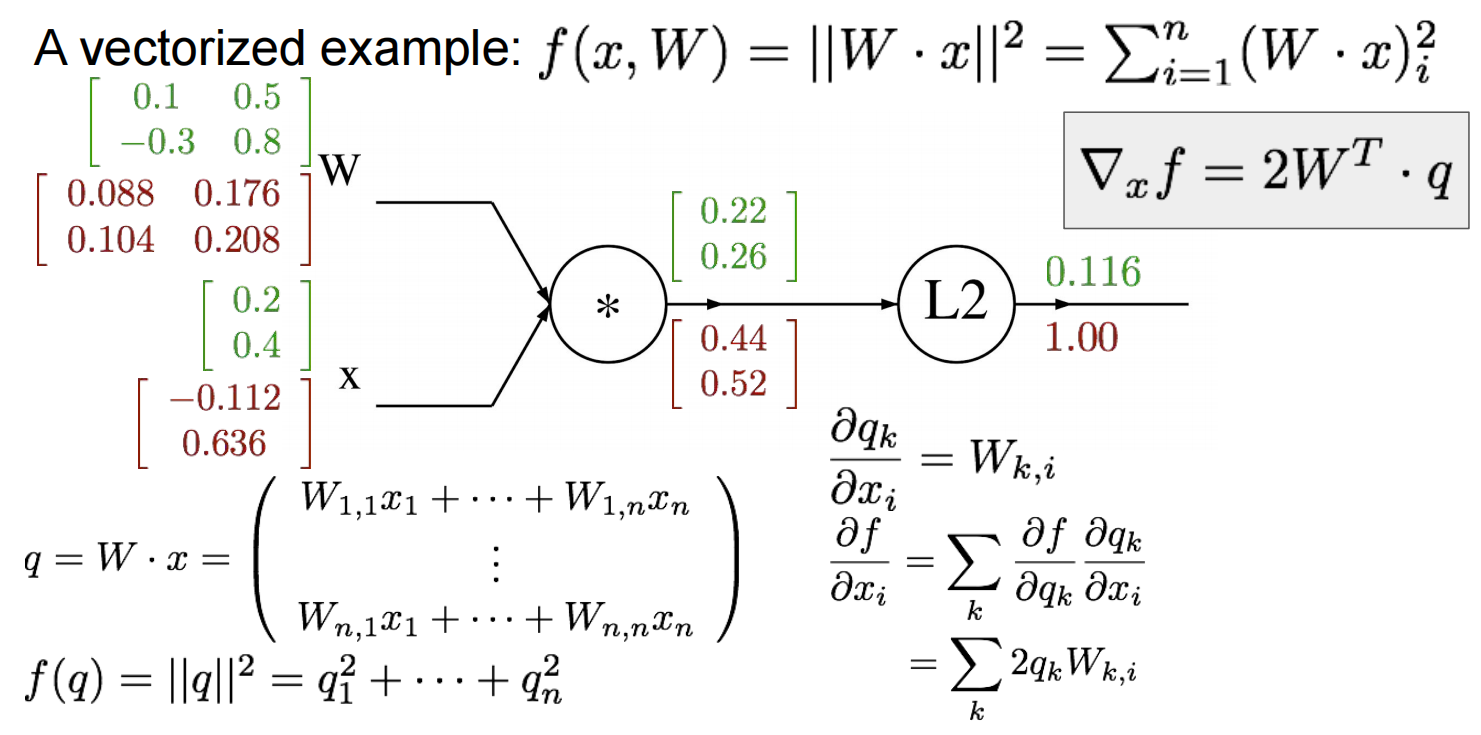
如果将数据向量化之后(因为真实场景下数据都是复杂且高维的,使用单一变量无法表示,所以需要知道如何用矩阵表示梯度,方便对高维数据的计算。)就变成了使用矩阵进行计算。
总结
通过加入非线性的因素,使得神经网络可以拟合非线性的数据,不仅仅拟合线性的数据。并且使用导数这一工具使得能够进行反向传播更新模型的权重,达到拟合数据的目的。