HOTR: End-to-End Human-Object Interaction Detection with Transformers
Motivation
- 大部分方法都是需要单独检测出人和 object 之后再对每一对关系进行预测。
- 单独预测出人和 object 之后再检测关系比较费时费算力,不够快。
Summary
本篇 paper 主要使用 Transformer 进行 HOI 检测。通过重新设计 DETR 的方式实现不需要通过一一匹配的方式来得到正确的 triplet,通过一个 encoder 和 两个 decoder (instance decoder 和 interaction decoder)实现对 triplet 的预测。并且提出了一种 HO Pointer 的方式来匹配。
Introduction
Sequential HOI Detectors:
- InteractNet:扩展了现有的目标检测器,引入了一个动作特定的密度图,基于以人为中心的外观来定位目标对象,并结合来自单个盒子的特征来预测交互。
- iCAN:一个以实例为中心的注意模块,它局部 object / 人 中提取与特征互补的上下文特征。
- No-Frills HOI detection:提出了一种仅使用简单的多层感知器的训练和推理HOI检测管道。
- Graph-based approaches have proposed frameworks that can explicitly represent HOI structures with graphs [24, 26, 4, 28, 21]:基于图的方法提出了可以用图[24,26,4,28,21]显式地表示 HOI 结构的框架。
- Deep Contextual Attention:提出了一种仅使用简单的多层感知器的训练和推理HOI检测管道。基于图的方法提出了可以用图[24,26,4,28,21]显式地表示HOI结构的框架。
- [28]:提出了一种异构图网络,将人和对象建模为不同类型的节点
- linguistic priors [23, 31, 17, 4, 1, 32, 20]
- human pose information [15, 33, 18, 9, 27, 33]
Parallel HOI Detectors:
- 这些工作直接定位了与交互点[30,19]或联合盒[12]的交互,用简单的基于启发式的距离或信息信息匹配取代了用于交互预测的单独神经网络。由于它们可以与现有的对象检测器并行化,因此它们具有快速的推理时间。
- 由于它们可以与现有的对象检测器并行化,因此它们具有快速的推理时间。然而,这些工作的局限性在于,因为它们需要一个手工制作的后处理阶段来将局部交互与目标检测结果联系起来。这个后处理步骤分为:
- 需要手动搜索阈值
- 生成额外的时间复杂度,以匹配每个对象对与本地化的交互(5∼9ms)。
受到 DETR 的启发
DETR [2]最近被提出,以消除在目标检测中需要许多手工设计的组件,同时展示了良好的性能。DETR 在通过解码器的一次通道中推断出一组固定大小的 个预测,其中 被设置为明显大于图像中的典型对象数量。DETR 的主要损失产生了预测对象和地面真实对象之间的最优二部匹配。随后,对目标特定的损失(针对类别和边界框)进行优化。
Methods
本文的目的是预测一组 <human, object, interaction> 的 triplets,同时以端到端的方式考虑这些 triplets 之间的内在语义关系。
为了实现这一目标,我们将 HOI 检测表示为集合预测的形式。在本节中,我们首先讨论将目标检测[2]的 triplet 预测结构直接扩展到 HOI 检测的问题。然后,我们提出了我们的架构 HOTR,它并行地预测了一组 object,并将交互中的人和对象关联起来,而 Transformer 中的自注意力则模拟了交互之间的关系。最后,我们给出了我们的模型的训练细节,包括匈牙利匹配的HOI检测和我们的损失函数。
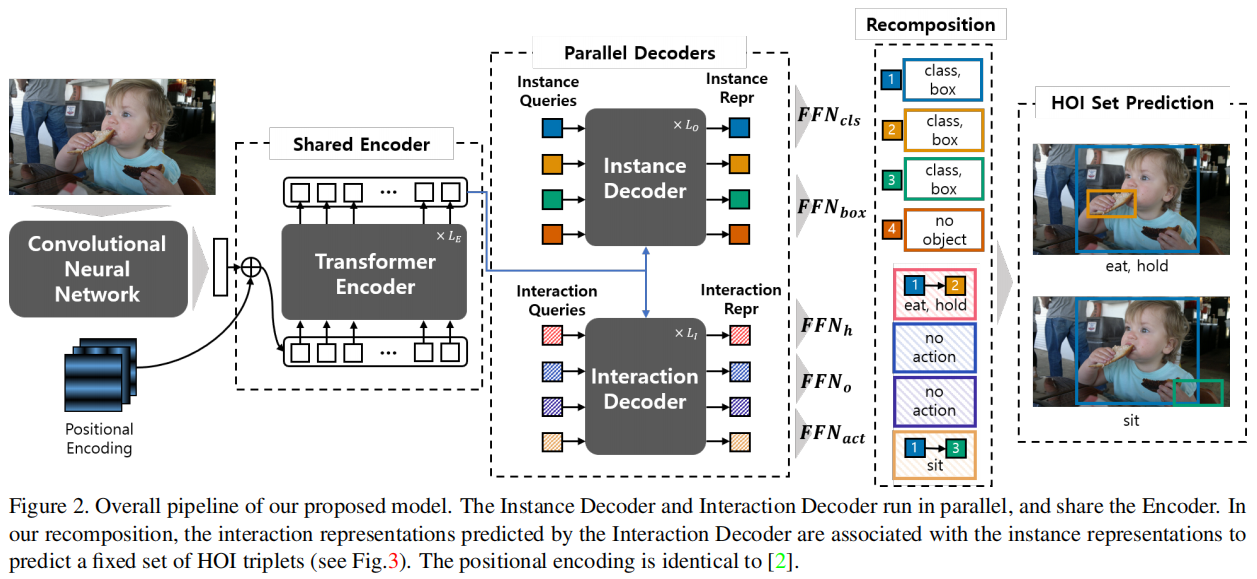
Architecture
HOTR的总体结构如图 2 所示。我们的架构的特点是一个 Transformer encoder-decoder 结构,带有一个共享的编码器和两个并行解码器(即,instance 解码器和 interaction 解码器)。这两个解码器的结果与使用我们提出的 HO Pointer 来生成最终的 HOI triplets 相关联。
Transformer Encoder-Decoder architecture
tip这里的交互表示为谓词动作。
与DETR [2]类似,全局上下文是由主干CNN和一个共享编码器从输入图像中提取出来的。然后,将两组位置嵌入(即实例查询和交互查询)输入到两个并行解码器(即图2中的 instance 解码器和 interaction 解码器)中。
instance 解码器将实例查询转换为用于目标检测的 instance 特征,而 interaction 解码器将 interaction queries 转换为用于交互检测的 interaction 特征。
我们将前馈网络(FFNs)应用于 instance 特征,得到了一个 Human Pointer,一个 Object Pointer 和 interaction type,见图3。换句话说,instance 表征过使用 Human Pointer 和 Object Pointer(HO指针)指向相关的 instance 表示来定位人的区域和 object 的区域,而不是直接回归 bbox。
与直接回归方法相比,我们的架构有几个优点。我们发现,当一个对象参与多个交互时,直接回归边界框会出现问题。在直接回归方法中,相同 object 位置在不同的交互中是不同的。我们的体系结构通过使用单独的 instance 和interaction 表征,并使用 HO Pointer 关联它们来解决这个问题。此外,我们的架构允许更有效地学习 object 的位置,而不需要为每个交互冗余地学习位置。请注意,我们的实验表明,我们的共享编码器比两个单独的编码器更有效地学习 HO Pointer
HO Pointers
图 3 说明了 HO 指针如何将来自 instance 解码器和 interaction 解码器的并行预测关联起来的概念性概述。HO指针(即,Human Pointer 和 Object Pointer)包含交互中的人和 object 的相应实例表示的索引。
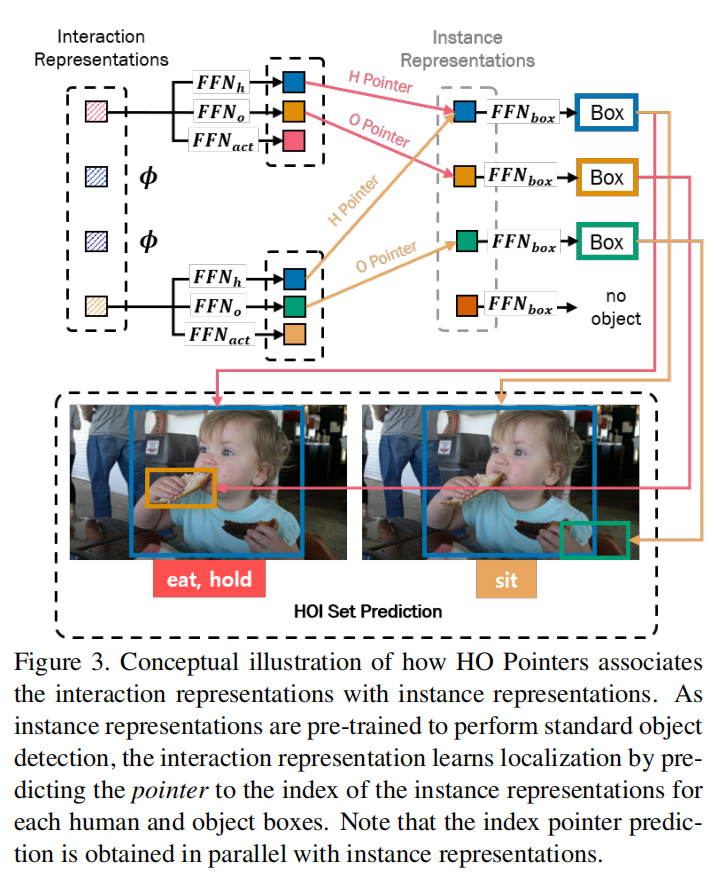
在 interaction decoder 转换 个 interaction queries 成 个 interaction 表征之后,interaction 表征 传入到两个 FFN 中,分别表示为:。为了得到向量 和 。也就是 和 。最后得到相似度得分最高的 instance 表征的索引 和 。
其中 是第 个 instance 表征和 。
Recomposition for HOI Set Prediction
从前面的步骤中,我们现在有了以下内容:
个实例表示 。
个 instance 表征 和它们的HO Pointer 和 。给定 交互类,我们的重组方法是应用 FFN 进行bbox 回归和 interaction 分类,分别为 和 。然后,得到第 个 interaction表示 的最终 HOI 预测的结果。
由我们的 HOTR 最终预测结果的 HOI 是 个 triplets 的集合,。
Complexity & Inference time
以往的并行方法已经用快速匹配的 triplets(将神经网络 interaction 区域与基于距离 [30] 或 IoU[12] 的相应的 human 区域和 object 区域关联起来)取代了昂贵的成对神经网络推理。HOTR 通过将 个 interaction 与 个 instance 关联起来,进一步减少了目标检测后的推理时间,从而降低了时间复杂度 。通过消除之前的一阶段 HOI 检测器的后处理阶段,包括 interaction 区域的 NMS 和 triplet 匹配,HOTR 减少了 4∼8 ms 的推理时间,同时显示出性能的改善。
Training HOTR
在本节中,我们将解释 HOTR 训练的细节。首先引入匈牙利匹配的代价矩阵,用于通过重组得到的 GT HOI triplet 和预测得到的 HOI 集合之间的唯一匹配。然后,利用匹配结果,我们定义了HO Pointer 的损失和最终的训练损失。
Hungarian Matching for HOI Detection
HOTR 预测了 个 HOI triplet,它们包括人的 bbox、object 框和 动作类型的二进制分类。每个预测都捕获一个独特的
<human, object>一个或多个 interactions。 被设置为大于图像中 interaction 对的类别数量。我们从基本代价函数开始,它定义了预测和 GT HOI triplet 之间的最优二部匹配,然后展示我们如何修改交互表示的匹配代价。设 表示 GT HOI triplet 的集合,而 作为 个预测的集合。由于 大于图像中唯一交互对的数量,我们也认为 也是一组大小为 的填充 (表示没有交互)。为了找到这两个集合之间的二部匹配,我们寻找 个元素 的排列:
\hat\sigma = \mathop{\text{argmin}}\limits_{\sigma\in \mathcal{S}_K}\sum^K_i\mathcal{C}_{match}(y_i, \hat y^_{\sigma(i)}),其中, 是 GT 和具有索引 的预测之间的成对匹配代价。但是,由于 是 的形式,而 是 的形式,所以我们需要修改成本函数来计算匹配成本。
设 是一个映射函数,从GT 到 GT 。使用逆映射 ,我们从 GT box 中得到GT idx。
设 是一组规范化的 instance 表征 ,即 。我们计算 ,这是对(1)中的 Human Pointer 的 softmax 预测集合,给定为:
其中,表示行向量的垂直方向 stack,以及 。 也是类似的定义。
给定 GT 和 ,我们通过 和 转换为索引,并计算我们的匹配代价函数写为:
其中, 表示第 行和第 列处的元素,而 为预测的动作。动作匹配成本计算为 。将 和 设置为常数,以平衡指数预测和行动分类的成本函数的不同尺度。
Final Set Prediction Loss for HOTR.
然后我们计算上面所有匹配的对的匈牙利损失,其中 HOI triplet 的损失有位置损失和动作分类损失为:
位置损失 记为:
其中, 是控制损失函数的平滑度的温度。我们通过经验发现, 是我们实验的最佳值。
Defining No-Interaction with HOTR
Implementation Details
我们用 AdamW [22]来训练 HOTR。我们将 Transformer 的初始学习速率设置为 ,权重衰减设置为 。所有 Transformer 的权重都用 Xavier init [7]初始化。为了与 baseline 进行公平的评估,backbone, encoder 和 instance 解码器在 MS-COCO中 进行了预训练,并在训练期间进行了冻结。我们使用 DETR [2] 中的比例放大,调整输入图像的大小,使最短的边至少为 480 像素,最多为 800 像素,而最长的边最多为 1333 像素。
Experiments
在本节中,我们将演示我们的模型在 HOI 检测中的有效性。我们首先描述了我们用作 baseline 的两个公共数据集: V-COCO 和 HICO-DET。接下来,我们展示了 HOTR 通过在 mAP 和推理时间上实现了最先进的性能,成功地捕获了 HOI triplet。然后,我们提供了对 HOTR 体系结构的详细消融研究。
Detail
Dataset:
Verbs in COCO (V-COCO)
trainval: 5400
test: 4946
对于 V-COCO 数据集,我们报告了 和 中 超过 25 个交互。这两种场景代表了对象遮挡情况的不同评分方法。在场景 1 中,模型应正确预测被遮挡物体的边界框为 [0,0,0,0],同时正确预测人的边界框和动作。在场景2中,该模型不需要预测被遮挡的对象。
HICO-DET
human-object pairs: 150K+
train: 37536
test: 9515
verb, object pairs: 600 types
对于 HICO-DET,我们在默认设置中报告我们的性能,其中我们评估在整个测试集上的检测。我们遵循之前的设置,报告了三个不同类别集的 mAP:
- HICO 中的所有 600 个 HOI 类别(Full)
- 138 个训练实例少于 10 个(罕见)
- 462 个有 10 个或以上训练实例的 HOI 类别(非罕见)。
Quantitative Analysis
对于定量分析,我们使用官方评估代码来计算 V-COCO 和 HICO-DET 的性能。表 1 和表 2 显示了 HOTR 与最新的 HOI 检测器的比较,包括 sequential 方法和 paralleled 方法。为了公平比较,实例检测器由 MS-COCO 中预训练的参数固定。V-COCO 数据集的所有结果都用固定检测器进行评估。对于 HICO-DET 数据集,我们使用遵循通用评估协议[1,18,10,21,4,16,12,19] 的固定检测器和微调检测器来提供结果。
我们的 HOTR 在 V-COCO 和 HICO-DET 数据集上实现了一个新的最先进的性能,同时是最快的并行检测器。表 1 显示了我们在同时包含场景 1 和场景 2 的 V-COCO 数据集上的结果。HOTR 在场景 1 中优于最先进的并行 HOI 检测器[30],其边际为 4.2mAP。
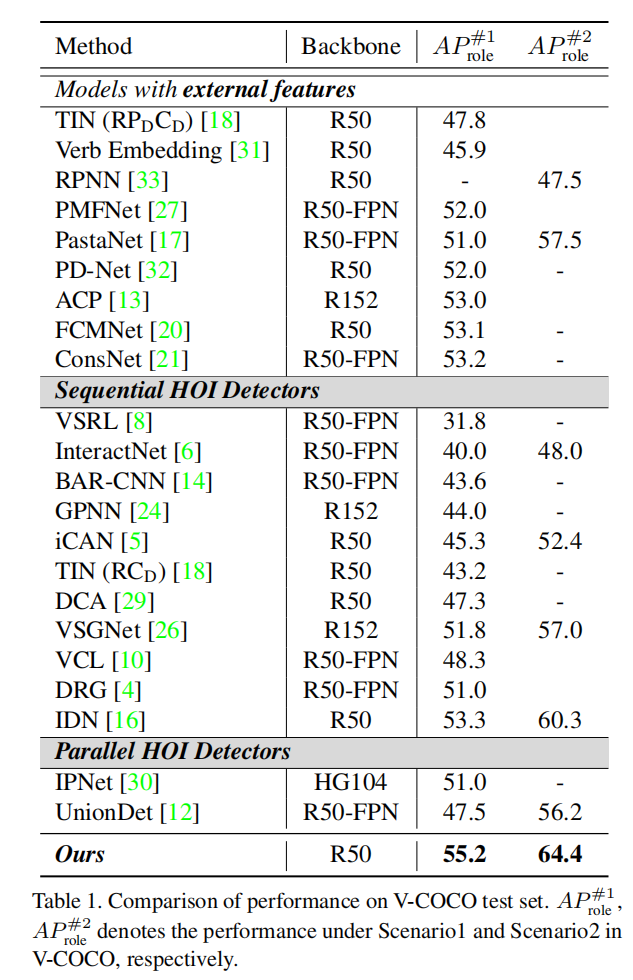
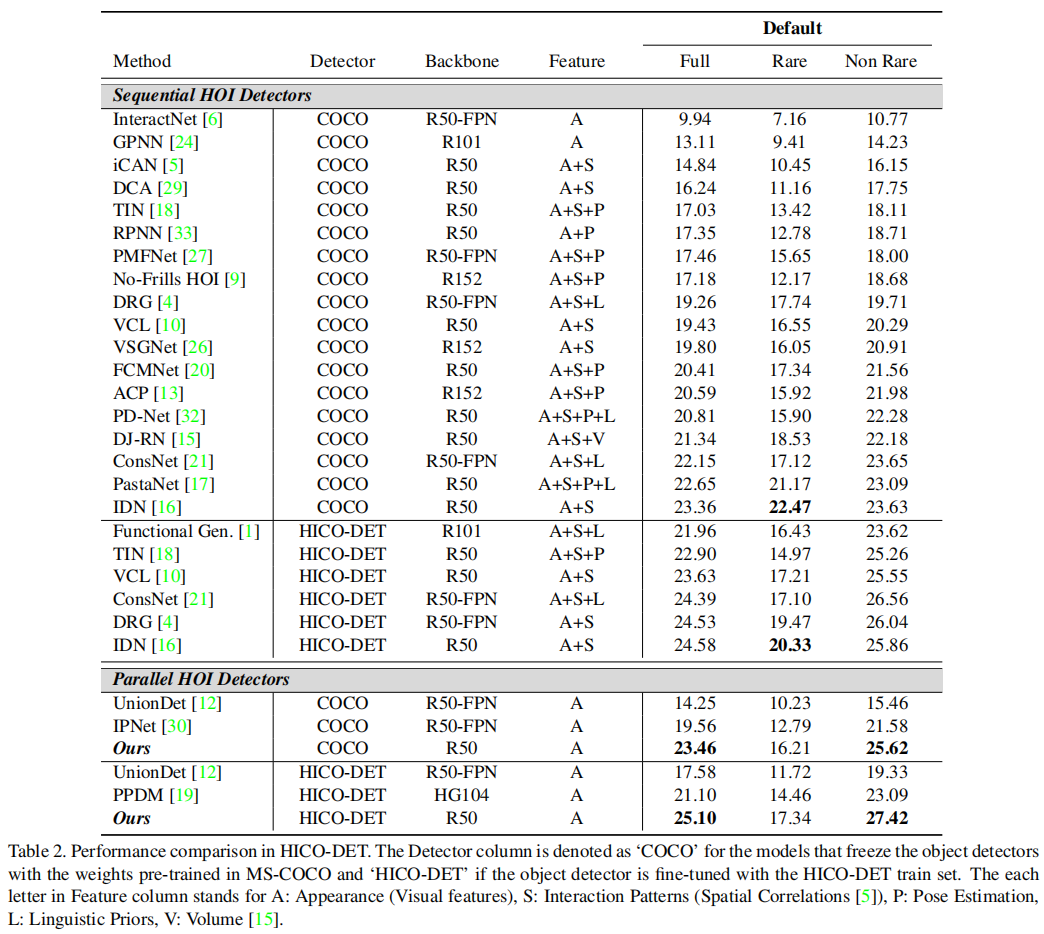
表2显示了每个 Full/Rare/Non-Rare 的默认设置中的 HICO-DET 中的结果。由于 HICO-DET 数据集中的对象的噪声标记,对 HICO-DET 训练集上的预训练对象检测器进行微调提供了一个有利于整体性能[1]的先验。因此,我们评估我们的性能在 HICO-DET 数据集在两个条件下:
- 使用预先训练的权重 MS-COCO 训练期间冻结(记为 COCO 探测器列)
- 性能后微调预先训练探测器 HICO-DET 训练集(记为 HICO-DET 探测器列)。在这两种情况下,我们的模型分别比最先进的并行 HOI 检测器优越于 4.1mAP 和 4mAP。
下面,我们将对我们的性能进行更详细的分析。
HOTR vs Sequential Prediction
在与表1和表2中总结的各种HOI方法进行比较分析时,我们还将HOTR的实验结果与顺序预测方法进行了比较。尽管顺序方法利用额外的信息而HOTR只利用视觉信息,HOTR优于先进的顺序高探测器[16]场景 1 和场景2 1.9 mAP 和4.1地图V-COCO而显示可比性能(边际0.1∼0.52 mAP)的默认(完整)HICO-DET评估。
Performance on HICO-DET Rare Categories.
在对图形化器数据集的完整评估中,HOTR显示了跨顺序和并行HOI检测器的最先进的性能(见表。 2).然而,在Rare设置下的HOTR的性能优于基线方法[16]。由于此设置处理的动作类别只有少于10个训练实例,因此如果没有外部特性的帮助,很难在此设置上实现准确性。因此,大多数在罕见环境中表现出高性能的研究都利用了额外的信息,如空间布局[5]、姿态信息[18]、语言先验[17]以及人类和物体[16]之间的一致性模式等。在这项工作中,我们的方法是一个完全基于视觉的管道,但如果我们包含先验知识,我们期望在Rare设置中进一步改进。
Time analysis
由于对象检测器网络的推理时间(例如,Faster-RCNN [25])可以根据基准设置(例如,lib,CUDA,CUDNN版本或超参数),时间分析是基于纯粹的推理时间的交互预测模型不包括对象检测阶段的时间与我们的模型。
对于详细的分析,HOTR的主干和编码器平均为 36.3 ms,实例解码器和交互解码器平均为 23.8 ms(注意两个解码器并行运行),重组和最终的HOI三重态推理平均为 0.9 ms。我们排除了所有模型中的i/o时间,包括之前的模型加载FasterRCNN的 RoI 对齐特征的时间(见图。1表示速度与时间的比较)。请注意,与最先进的并行HOI检测器相比,我们的 HOTR 运行 ×5∼×9 更快,因为一个显式的后处理阶段来组装检测到的对象和交互区域被一个简单的 搜索来推断HO Pointer 所取代。
Ablation Study
消融实验结果如下:
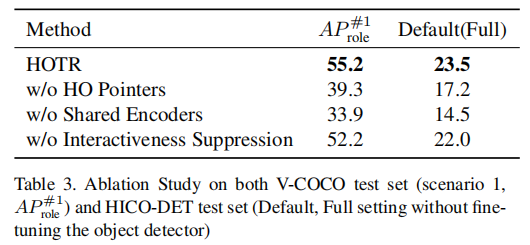
是否使用 HO Pointer
在HOTR中,交互表示通过使用 Human Pointer 和 Object Pointer(HO指针)指向相关的实例表示来定位人所在的区域和物体所在的区域,而不是直接回归边界框。我们认为,与直接回归方法相比,我们的架构具有优势,因为当一个物体参与多个交互时,直接回归每个交互预测的边界框需要对同一对象进行冗余的边界框回归。基于性能差距(V-COCO 的 55.2→39.3,HICO-DET 的23.5→17.2),可以得出结论,使用 HO Pointer 缓解了直接回归方法的问题。
Shared Encoder 和 Separate Encoder 的比较
从图 2 中,可以考虑为每个实例具有独立编码器和交互解码器的体系结构。在此消融实验中,我们验证了 HOTR 的共享编码器的作用。在表 3 显示,在 V-COCO 和 HICO-DET 中,Shared Encoder 的性能分别为 21.3mAP 和 9.0mAP。我们假设其原因是 Shared Encoder 帮助 Decoder 学习通用的视觉模式,因此 HO Pointer 可以共享整体上下文。
是否使用 Interactiveness Suppression
与基于 softmax 的分类不同,在该分类中,最大化 no-object 类的概率可以明确地减少其他类的概率,而动作分类是一种多标签二值分类,它独立地处理每个类。因此,HOTR 设置了一个显式的类来学习交互性,并抑制对具有低概率的冗余对的预测。表 3 显示,为交互设置显式类对最终性能贡献 3mAP。
Conclusion
在本文中,我们提出了第一个基于 Transformer 的人机交互问题中的集合预测方法 HOTR。HOTR 的集合预测方法消除了以前的 HOI 检测器的手工制作的后处理步骤,同时能够建模交互之间的相关性。
我们提出了各种 HOTR 的训练和推理技术:使用并行解码器进行 HOI 分解,基于相似性的重组层进行推理,以及交互抑制。我们开发了一种新的基于集的 HOI 检测匹配方法,它将交互表示与指向实例表示关联起来。
我们的模型在 HOI 检测的两个数据集上取得了最先进的性能: V-COCO和HICO-DET的性能,与以前的并行 HOI 探测器有显著的优势。HOTR 在 HOI 检测推理时间下的两个基准数据集上取得了最先进的性能,比以前的并行 HOI 探测器(5∼9ms)要快得多。