Chapter2 Data Structure
Attention:
- 一般在写算法题的时候都是用数组来模拟各种数据结构,因为使用结构体每次都要使用 new 创建对象,这个过程非常慢!
- 算法题一般不用纠结浪费的问题,只需要在特定的时间之内运行完程序就行。
- 算法题不用纠结空间的问题,目光放在时间上即可。
- 读字符建议用字符串来读取
Link List
Single(邻接表)
用得比较多的是邻接表,邻接表用于存储树和图。
用数组表示的方法:
- 创建
e[N]数组表示链表中节点的值。 - 创建
ne[N]数组表示链表当前节点的下一个,也就是指向下一个节点的指针。
- 创建
对应关系为
用下标来表示,
e[0]表示链表中 0 号节点的值,ne[0]表示链表中 0 号节点的下一个指向的节点的下标。下图可说明。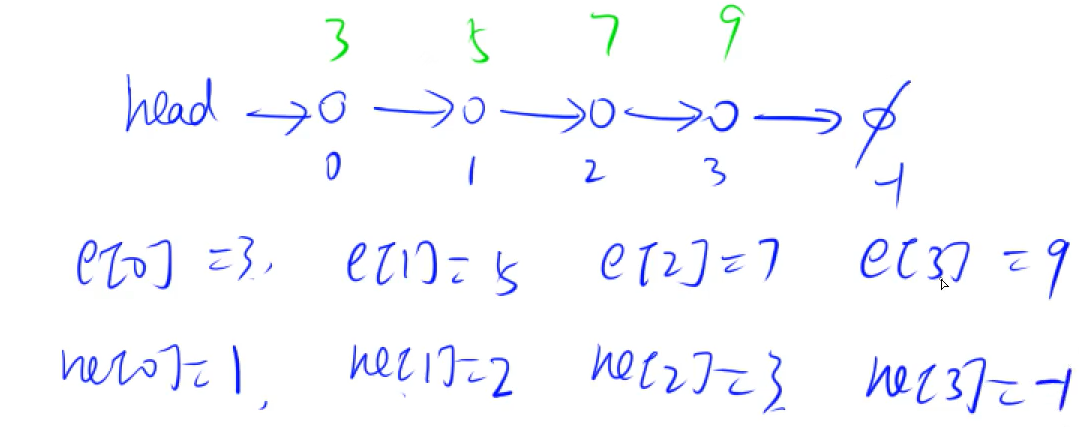
其中,当指向的下一个节点为空时用 -1 表示。
Dual
主要用于优化,具体看题目。双链表就是有两个指针,一个指向前面,另一个指向后面。
规定下标为 0 的点为头节点,下标为 1 的点为最后一个点
用数组的表示方法:
创建
e[N]数组表示链表中节点的值。创建
l[N]和r[N]分别表示链表当前节点的左指针和右指针,分别指向前一个节点的 idx 和 后一个节点的 idx。(l 表示指向左边的,相当于向左的单链表的ne[N};r 表示指向右边的,相当于向右的单链表的ne[N}。)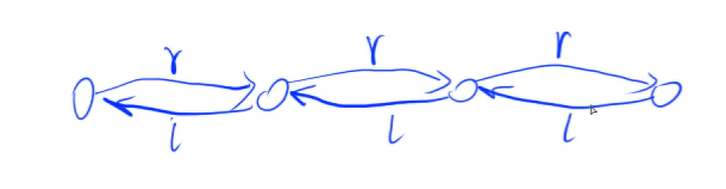
Stack
普通栈
先进后出
const int N = 1e6 + 10;
int tt, stk[N];
void insert(int x) { stk[++tt] = x; }
void remove() { tt--; }
int top() { return stk[tt]; }
bool isEmpty() {
if (tt > 0)
return 0;
else
return 1;
}
- 单调栈
思考思路:
1.与双指针类似,先思考暴力做法。
2.在暴力基础上思考可以优化地方,思考有哪些性质。
3.写算法题基本都是用空间换时间。
典型例题:求一个序列当中每一个数的左边离这个数最近的且比它小的数,不存在返回 -1。
扫描顺序如图(其中,绿色为当前数字,橙色为判定区域):

结果为(黄色和黑色加粗为当前数字的结果,也就是绿色格子):
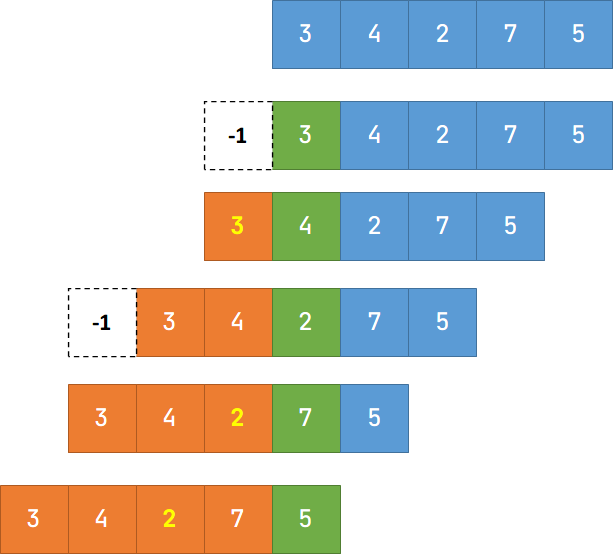
本题中,定义一个栈来存储左边的元素,每扫描一个元素就往栈当中添加当前元素进来。通过观察栈中元素的性质构造一个单调序列, 且 ,如果 作为目标值输出,那么 也可以输出,所以 就可以被去掉。满足这个性质点都可以被剔除,这些点是没有用的点,可以删除,最终剩下的点就构成一个单调的序列。
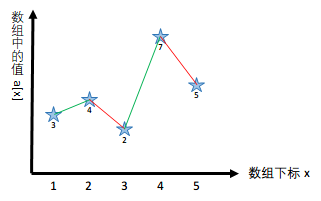
上图中,本质上可以看成划分了多个局部的单调序列。只要出现递减的数,就重新构造单调子序列。
对于 3 而言,没有左边的元素,所以是 -1;
对于 4 而言,左边比它小的第一个数为 3, 所以是 3;
对于 2 而言,没有左边比它小的。所以是 -1;(此时扫描到这个数后,相对于前面的序列已经出现递减,故这里是第二个子序列的开始)
对于 7 而言,左边比它小的第一个数为 2,所以是 2;
对于 5 而言,左边比它小的第一个数为 2,所以为 2;(此时扫描到这个数后,相对于前面的序列已经出现递减,故这里是第三个子序列的开始)
所以,综上可以发现,所求的目标值都是每个单调子序列的第一个元素,使用栈进行存储后即为栈顶元素,栈每次都会存储当正在扫描的元素所在的子序列,当遇到递减的元素后就清空栈,重新记录单调子序列。(本质,构成逆序对的点可以被删除。)
Queue
普通队列
先进先出
const int N = 1e6 + 10;
// 队尾插入元素,队头弹出元素
int hh, tt = -1, q[N];
void insert(int x) { q[++tt] = x; }
void remove() { hh++; }
int front() { return q[hh]; }
int back() { return q[tt]; }
bool isEmpty() {
if (hh <= tt)
return 0;
else
return 1;
}
单调队列
与单调栈类似,典型例题:滑动窗口,输出每次窗口当中的最值。(计算机网络重要应用)
求最小值:当队列(滑动窗口)当中存在一个比最小的数时,其他的数永远都不可能是最小,也就是其他数字永远都不会当成答案输出(性质)。所以其他数字就可以被剔除。(本质,构成逆序对的点可以被删除。)构造出一个单调子序列之后,最小值会在队头出现。(最大值同理)
KMP
- 先思考暴力的做法。
- 如何优化
对于模板字符串的每一个元素都需要模拟出来一个以某点为终点的后缀,得出相等的最大长度是多少。创建一个 next[N] 数组,next[i] 表示的含义是以 i 为终点的后缀和从 1 开始的前缀相等,且后缀的长度最长。其中对于 next[i] = j 表示 。
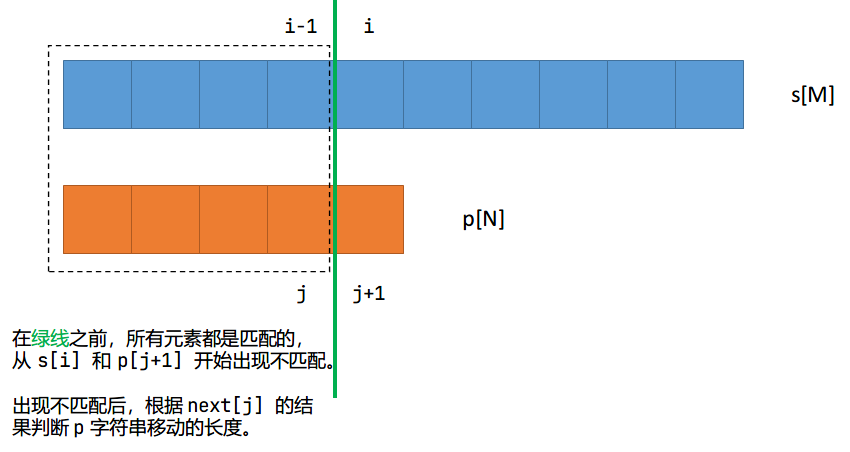
使用 next 数组进行匹配,一开始判断 s[i] 是否与 p[j + 1] 相等,如果不相等,则需要通过 next 数组移动模板串的位置,修改 j 的值实现 j = ne[j]。如果相等,则继续往后匹配,直到 ,也就是扫描到模板字符串 p 的末尾说明匹配成功,此时对应起始的点下标就是 ,记得修改 的位置,因为匹配成功之后因为已经到达模板串的末尾,通过 next 数组告诉模板串 移动多少距离 可以找到下一个匹配的字符串(j = ne[j])。
求解 next 数组
两个模板串向右错开一位后,对模板串扫描前缀和后缀相同的部分。

匹配字符串
字符串和模板串向右错开一位进行匹配,根据 next 数组的结果扫描前缀与后缀相同的部分。
Trie
Trie:高效存储和查找字符串集合的数据结构。以字典形式存储。本质为字典树。将数据按照在树中的 DFS 方式存储。也可以叫前缀树,根据前缀一个一个查找。注意每个数据的结束一定要在对应的末尾进行标记,表示数据存在。
使用的时候注意树的横向和纵向所代表的意思(二维数组的第 1 维和第 2 维的定义,从左往右看),一般来说第 1 维表示位置即层数,第 2 维度仅表示对应的键。使用 DFS 找到对应的数据。
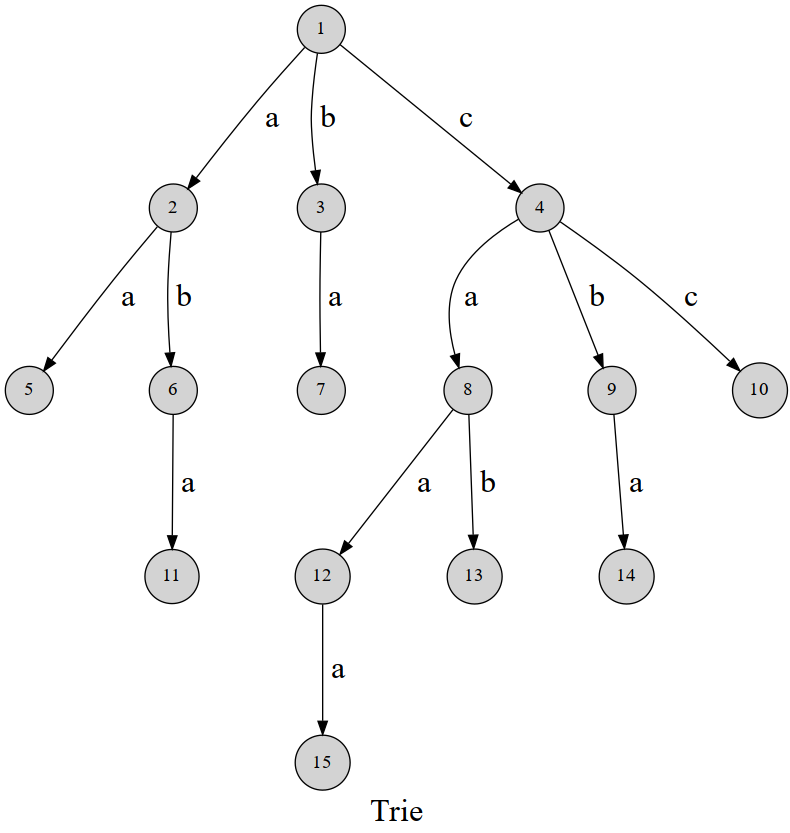
上述 Trie 树表示如下为 aa, aba, ba, cc, cba, cab, caaa。(叶子节点作为结束)
并查集
- 简短且思路精巧,最容易考到,重点!
- 用于快速维护一些操作
- 将两个集合合并
- 询问两个元素是否在一个集合当中
基本原理:
用树维护一个集合,根节点的编号表示当前集合的编号。每个节点存储它的父节点,p[x] 表示 x 的父节点。
- 判断树根:
if (p[x] == x) - 求 x 的集合编号:
while(p[x] != x) x = p[x]; - 合并两个集合:p[x] 是 x 的集合编号,p[y] 是 y 的集合编号。
p[x] = y
- 判断树根:
对于上述的优化
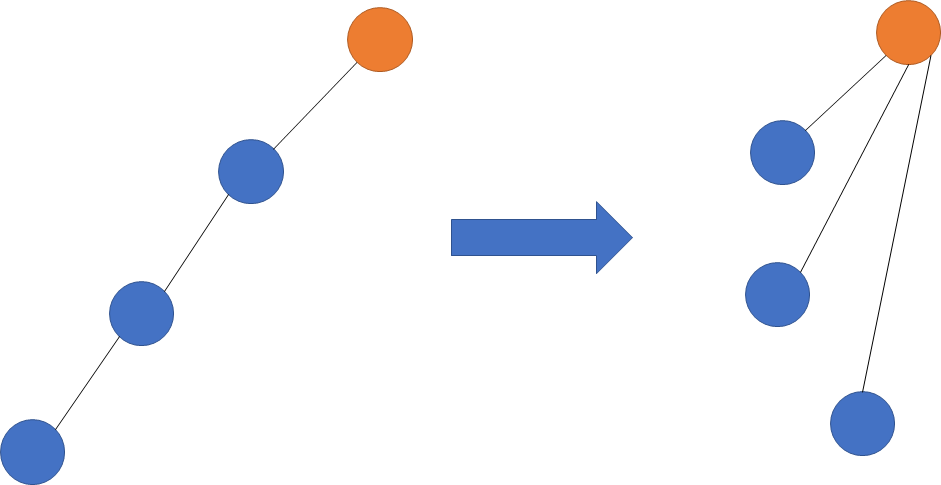
- 第一次找到一条路径后,将这条路径上所有的节点都与根节点相连。本质上是路径压缩优化。
int find(int x) {
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
Heap
堆常用操作:
- 插入一个数
- 求集合当中的最小值
- 删除最小值
- 删除任意一个元素
- 修改任意一个元素
堆本质是一个完全二叉树,最后一层往上全满,最后一层从左到右依次排列。
小根堆:每一个点都是小于等于左右的节点
大根堆:每一个点都是大于等于左右的节点
存储方式:数组存储,偶数存左节点,奇数存右节点。编号为 的节点,左节点编号为 ,右节点编号为 (下标从 1 开始)
操作(看实际需求决定使用哪个函数):
down(x):将大数 x 沉到树的底部。
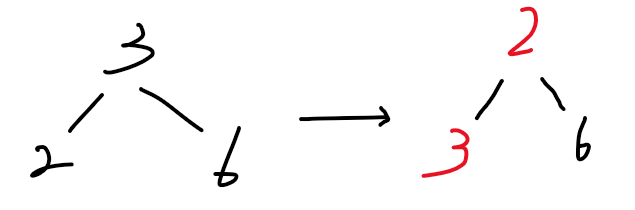
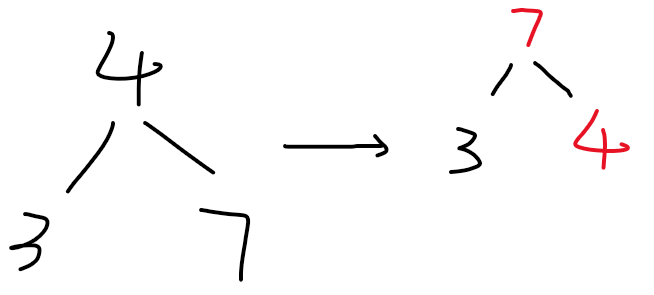
up(x):将小数 x 浮到树的顶部,即根节点。
插入一个数:
heap[ ++size] = x; up(size);(在数组后面插入,再将整个堆调整一下)求集合当中的最小值:
heap[1];(小根堆的根节点为最小值)删除一个最小值:
heap[1] = heap[size]; size--; down(1);(用最后一个点代替掉根节点,随后再调整堆)删除任意一个元素:
heap[k] = heap[size]; size--; down(k); up(k);(用最后一个点代替掉第 个点,随后上下调整堆)修改任意一个元素:
heap[k] = x; down(k); up(k);(更新第 个点,随后上下调整堆)
down 和 up 操作:
int h[N], size;
int heap_swap(int a, int b) {
swap(ph[hp[a]], ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
void down(int u) {
int t = u;
if (u * 2 <= size && h[2 * u] < h[t]) t = 2 * u;
if (u * 2 + 1 <= size && h[2 * u + 1] < h[t]) t = 2 * u + 1;
if (u != t) {
swap(h[u], h[t]);
down(t);
}
}
void up(int u) {
while (u / 2 && h[u / 2] > h[u]) {
swap(h[u / 2], h[u]);
u /= 2;
}
}
Hash Map
哈希表最主要的作用是将一个值域比较大的空间映射到比较小的空间。
哈希表一般都只会添加元素,不会删除元素,只会在不要的元素打一个标记。
基本存储结构
原理:通过一个哈希函数,将比较大空间的值域进行映射。将不同的数映射到另一个值域空间内。在哈希函数发生冲突的时候,通过对应的方式来解决。
哈希函数:通过取模进行映射,模数一般选取质数。$h(x)=x\ mod\ n $(n 取质数)
寻址(解决冲突)方法:开放寻址法,拉链法
- 拉链法:一个数组当中每一个元素还是一个数组,类似于一个拉链,所有冲突的数都会存到这条拉链,也就是对应元素的数组。
- 开放寻址法:数组长度开到最大范围的两到三倍之间,遇到冲突后位移 n 个位置,直到找到空位为止。
字符串哈希的使用方式:
字符串哈希值本质上是用来区别两个字符串是否相等,因为将字符串通过类似进制的方式进行编码,使得对于每一个字符串都具有唯一的属性,当两个串的哈希值相等时,说明这两个字符串是一定相等的。
将一个字符串看成 k 进制的数,把字符串转换成数实现。
是一个处理字符串的利器。
字符串哈希定义:通过一个数组 h[N],则 h[k]表示的是字符串前 k 个字母的哈希值。(前缀哈希)
前缀哈希定义:把字符串看成一个 进制的数,每一位上的字母就表示 进制的每一位数。因为字符串长度很长,得出的数会比较大,所以一般会将数字取模,模数为 。
danger- 字符串映射成数字不能映射成 0,因为如果一位表示成了 0,那么多次重复这个字母导致得出的结果还是一样的,无法进行区分。
- 假定不存在冲突。条件是: 或者 且
得出前缀哈希之后,本质上就是前缀和,就可以得出任意子串的哈希值。知道前缀哈希后,通过
h[R] - h[L - 1]计算出子串哈希值。计算的时候需要将子串进行对齐,就类似计算二进制数的时候要逐位对齐;。所以,只需要 即可。最后结果只需要通过unsigned long long进行存储,因为 正好是这个类型的范围,只需要让这个数溢出就能实现取模的效果。
STL
- vector,变长数组,倍增的思想
- string,字符串, substr(), c_str()
- queue,队列,push(), front(), pop(), back()
- priority_queue,优先队列,push() , top(). pop()
- stack,栈,push(), top(), pop()
- deque,双端队列
- set,map,multiset,multimap,基于平衡二叉树(红黑树〉,动态维护有序序列
- unordered_set,unordered_map,unordered_multiset,unordered_multimap,哈希表
- bitset,压位,将字节存储转换为按位存储。